
接下来从场景出发,探讨HoloLens结合认知服务可以如何在业务场景中发挥优势,并给出实现难度评级,然后提出予力众生的设想和思路。
场景一:借助HoloLens提升客舱服务质量
新闻报道:
“近日某航空公司宣布,他们正在讨论尝试将HoloLens用于机上服务。在该航空公司描述的系统中,佩戴着HoloLens的空乘人员将能通过人脸识别技术识别出乘客,检索出他们的国籍、目的地、身体情况、过敏史,甚至他们最后一次要饮品的时间间隔。除此之外,该项目还希望通过视觉和音频线索探测出乘客的情绪。空乘人员可以看到乘客的情绪由平静变得焦虑,继而恢复平静。从长期来看,对于那些在来回走动而且双手不空闲的空中服务人员来说,增强现实头显是他们查看信息的一个好的工具。”
客舱服务的挑战:
个性化,飞行中往往需要服务乘客的各种个性化需求,需要准确及时查询客户的信息
特殊情况,不可避免,需要及时了解乘客的情绪波动,预警可能发生的特殊情况
MR+AI解决方案:
1. 通过HoloLens结合图像识别技术识别乘客的身份(人脸API)
2. 识别乘客的情绪(情绪API)
3. 为乘客提供更优质服务的同时解放双手(Heads up, hands free特性)
可落地难度总体评估:
第2和3点易于实现,难度较低;第1点需要预先训练再使用面部识别,难度适中。
扩展方案思路:
A. 结合HoloLens的空间记录存储乘客对应位置信息(Spatial awareness特性)
B. 结合认知服务提供多种语音翻译(翻译工具语音API)方便与乘客交流
C. 通过语音指令(必应语音API、语言理解智能服务LUIS、知识探索服务API)搜索特定的信息
D. 预测客户需求并给出智能的推荐和决策(自定义决策服务)
该场景可落地难度总体评估:
A. 需要将身份信息与空间信息对应,难度适中;B. 实现难度较低,但提高翻译准确度难度较大;C. 易于实现,难度较低;D. 需要足够的上下文数据,难度适中。
场景二:为所有人设计的MR体验
予力众生:
我们需要思考让混合现实为所有人带来便利,通过将HoloLens与AI结合,可以有很大可能更好地解决不同的人在使用HoloLens时的难点。
MR+AI解决方案:
1. 对于不便于用手势、不方便看的人,可以结合语音和语言服务利用语音和HoloLens交互(必应语音API、语言理解智能服务LUIS)
2. 对于不方便听和说的人,可以结合语言服务(语言理解智能服务LUIS)准确识别出意图后利用视觉图像反馈与之进行交互
可落地难度总体评估:
第1点易于实现,难度较低;第2点需要考虑如何快速进行文字输入,需要视觉反馈准确反映意图,总体难度适中。
HoloLens与微软认知服务结合的实战示例
实战一:Intelligent Bot in HoloLens
目标:
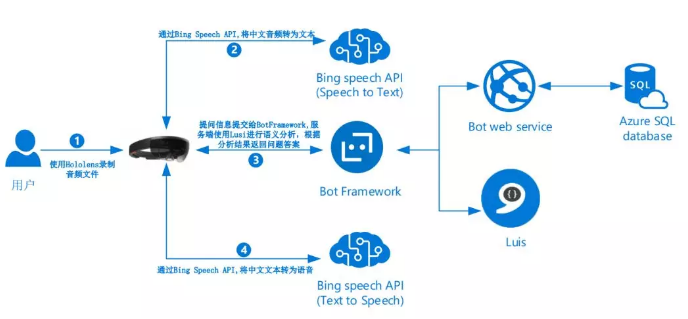
使用认知服务的Bing语音API, 语言理解智能服务LUIS以及Bot Framework实现在HoloLens应用内的中文语音交互问答。
关键技术包括:
- 语音处理:使用Bing语音API的语音到文本转换、文本到语音转换功能
- Bot框架:使用Direct Line通道传输问答数据
- 语言理解:使用语言理解智能服务自定义语言模型(包括构造目的/实体)
应用架构如下:
遇到的问题和挑战:
录音的启动停止是重要的环节,处理不好将会影响体验,最简单的方式是手动点击开始,点击停止,但在HoloLens上做频繁的Air tap操作会增加操作的复杂度,我们后来改成了设定固定时长,但是这样会有两个问题,一是有可能还没说完就停止采集,二是在问话简短的时候仍会增加需要传输的Wav文件的大小,增加传输延迟。
解决方法:
在采集时判断是否有显著的幅度升高,即为录音开始,在达到一定的低阈值条件后,即判断为静音,结束录制。
实战二:Custom Vision in HoloLens
目标:
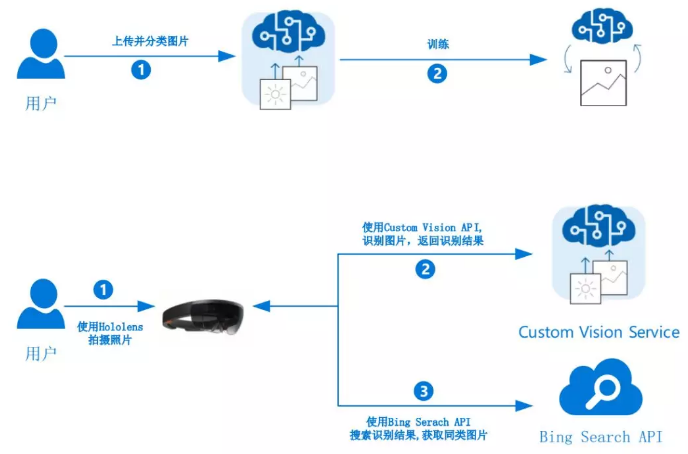
使用HoloLens拍摄照片后调用认知服务的自定义影像服务Custom Vision API实现画作识别,判断出是哪位画家的作品,并结合Bing Search实现相关作品搜索功能。
关键技术包括:
- 图片训练:在自定义影像服务中进行图片标记、训练、迭代和训练集预测
- 获取图片:使用HoloLens内置Camera拍照
- 搜索信息:使用必应图片搜索API获得更多相关信息
应用架构如下:
遇到的问题和挑战:
在自定义影像服务中训练模型比较容易,但最终画作的识别率依赖于HoloLens拍摄的照片质量,尤其是其中要识别的目标物体在整张照片中的比例,尽管我们可以在拍照时贴近画作使其在图片中占比较大,但是HoloLens仍会将多余的场景摄入。
解决方法:
我们加入了裁剪功能,可以在拍摄完成后根据实际情况使用拖拽手势进行关键部分裁剪,并将处理后的图片用作识别,识别准确率大大提升。