
HoloLens通过安装在设备上的传感器和输入技术,(其中包括声音输入、手势输入、眼动识别)实现用户混合现实场景下的交互行为。HoloLens有三种交互模型,适合多场景下的混合现实体验。这三种交互模型反应了用户心理模型。
交互模型包括:手和运动控制器、免动手操作、凝视和提示。
手和运动控制器
适合与3D空间的操作,用户可以通过手势操作选中空间中的虚拟3D物体,通过头部移动进行移动,利用6Dof追踪,将物体自由地置于空间中的任何位置。利用结合视觉和惯性器件的slam技术得到高精度的6dof追踪结果,能够更好的实现放置的准确性。
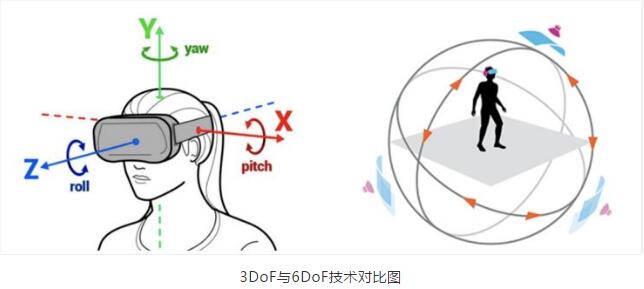
这两种技术支持了用户能够自如地用双手将空间中看到的虚拟物体随意摆放。人在和空间中虚拟物体交互时,最舒适的方式是抓取和摆放。因此,手和运动控制器适用于用户在3D空间中与虚拟3D物体交互的绝大部分场景。
免动手操作
适合解放双手的操作,适用于用户培训、维修及浏览等场景。用户无需动手操作,就可以通过眼镜设备中的声音获取信息。用户还可以通过长时间注视某按钮进行必要的按钮触发操作。这样的确省事不少。然而用户在浏览的过程中会遇到一种不便的常用操作,即进度调控操作。在交互上,用户就可以通过这样的规则长时间聚焦按钮自动触发的方式激活“下一页”的按钮触控,从而实现上下翻页,当然也可以通过语音交互的方式选择上下步骤跳转。
针对长时间聚焦按钮实现点选行为,HoloLens给了这样的规则说明:
1.初动延迟 :当用户开始看着目标时,系统不应立即响应,否则可能给用户带来不愉快的体验,致用户精疲力尽。这种情况下,我们会启动一个计时器,用于检测用户是在有意盯着该目标,还是仅仅瞟了它一眼。
2.启动停留反馈:在确定用户是在有意盯着该目标以后,我们开始显示停留反馈,通知用户停留激活正在启动。在设定好临近度(即用户在注视而不是瞟着某个大型目标)的情况下,建议将初动时间设置为 150-250 毫秒。
3.持续反馈:当用户持续看目标时,显示一个连续进度指示器,用户就知道自己必须始终看着目标。对于眼睛凝视输入,建议一开始显示一个较大的圆圈或球体,然后将其缩小,通过这种方式吸引用户的视觉注意力。显示一个表示最终状态的指示器(小圆圈)是为了告知用户停留将何时结束。
4.完成:如果用户一直注视该目标(又注视了 650-850 毫秒),则完成停留激活,选择被用户注视的目标。
简单的翻页操作可以以这样的交互方式满足,但如果遇到步骤过多,需要选择某一步骤的情况时,就需要考虑界面中增添唤起步骤选项的菜单。这些都需要在实战应用中不断摸索,寻找更合适的交互逻辑跳转方式。
凝视和提交
点击式体验。MR场景中大部分需要用到点击的交互行为。凡是界面中涉及到按钮的都需要通过点击来实现。而现在的AR设备/MR设备有一体式的,有分体式连box主机的(计算存储都在box里),也有连接手机的,甚至还有连接电脑的。这时候点击的操作会有很多方式:通过手势;通过设备本身的硬件按钮操作;通过遥控器;也有通过移动设备;甚至会有通过适配的外接设备例如鼠标,键盘等来实现点击的操作。
以上的交互方式虽然能够适用于大部分的MR/AR交互的使用场景,但并未全部涵盖,比如利用AR/MR设备实现键盘打字,现阶段还未体验到较流畅的交互方式。
除了人与机器本身的交互方式,当AR或MR设备配置外部遥控设备或移动设备做控制器。